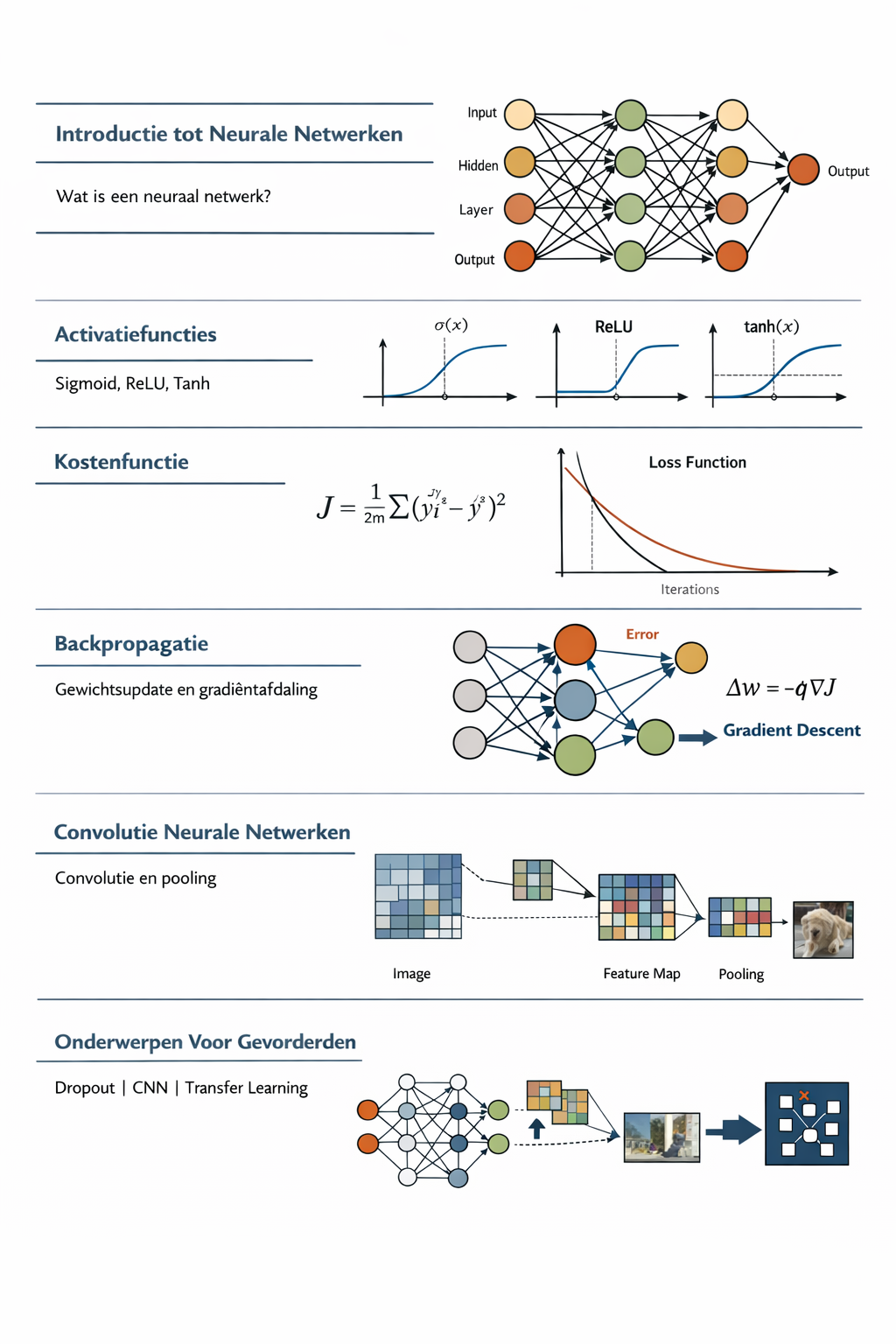
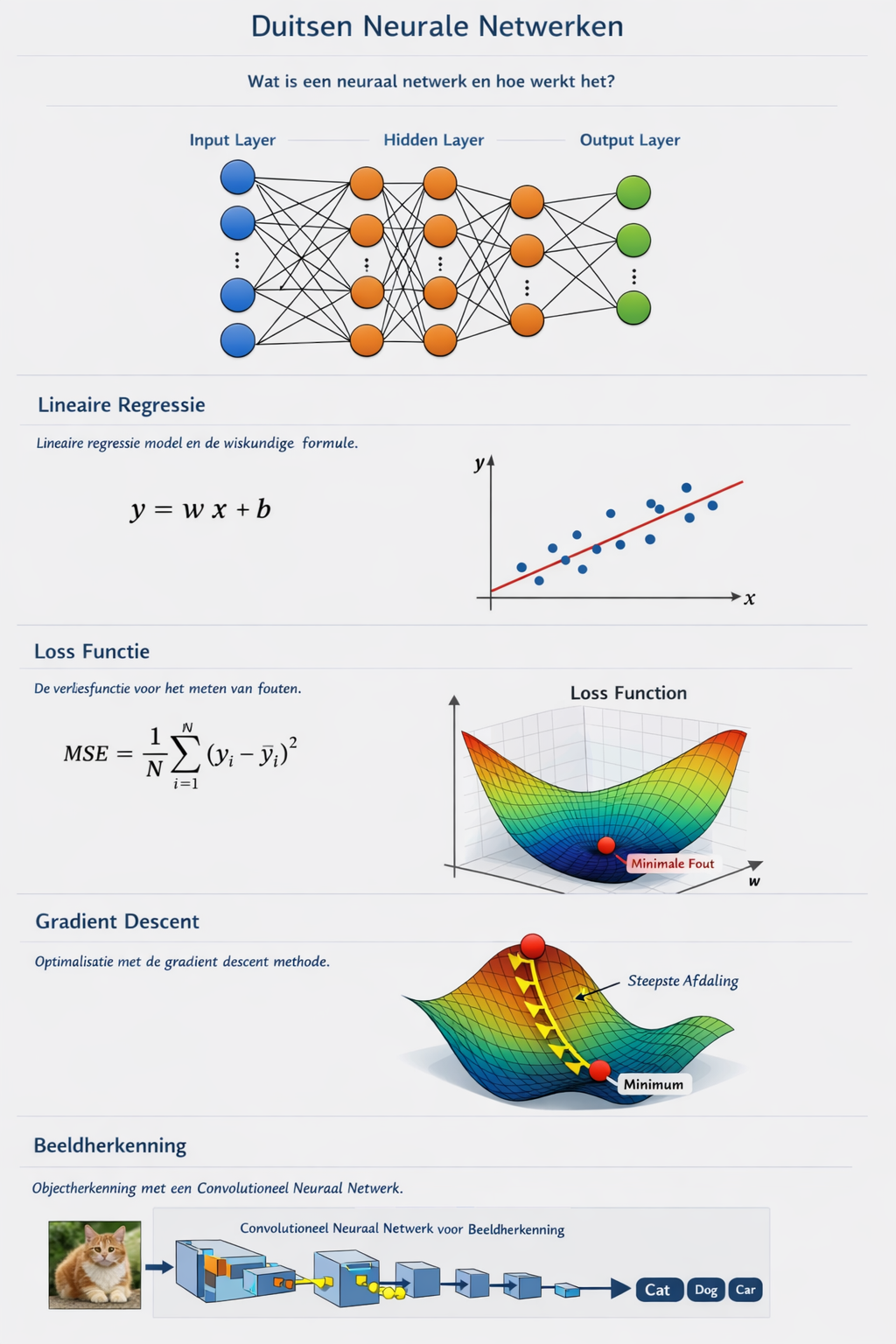
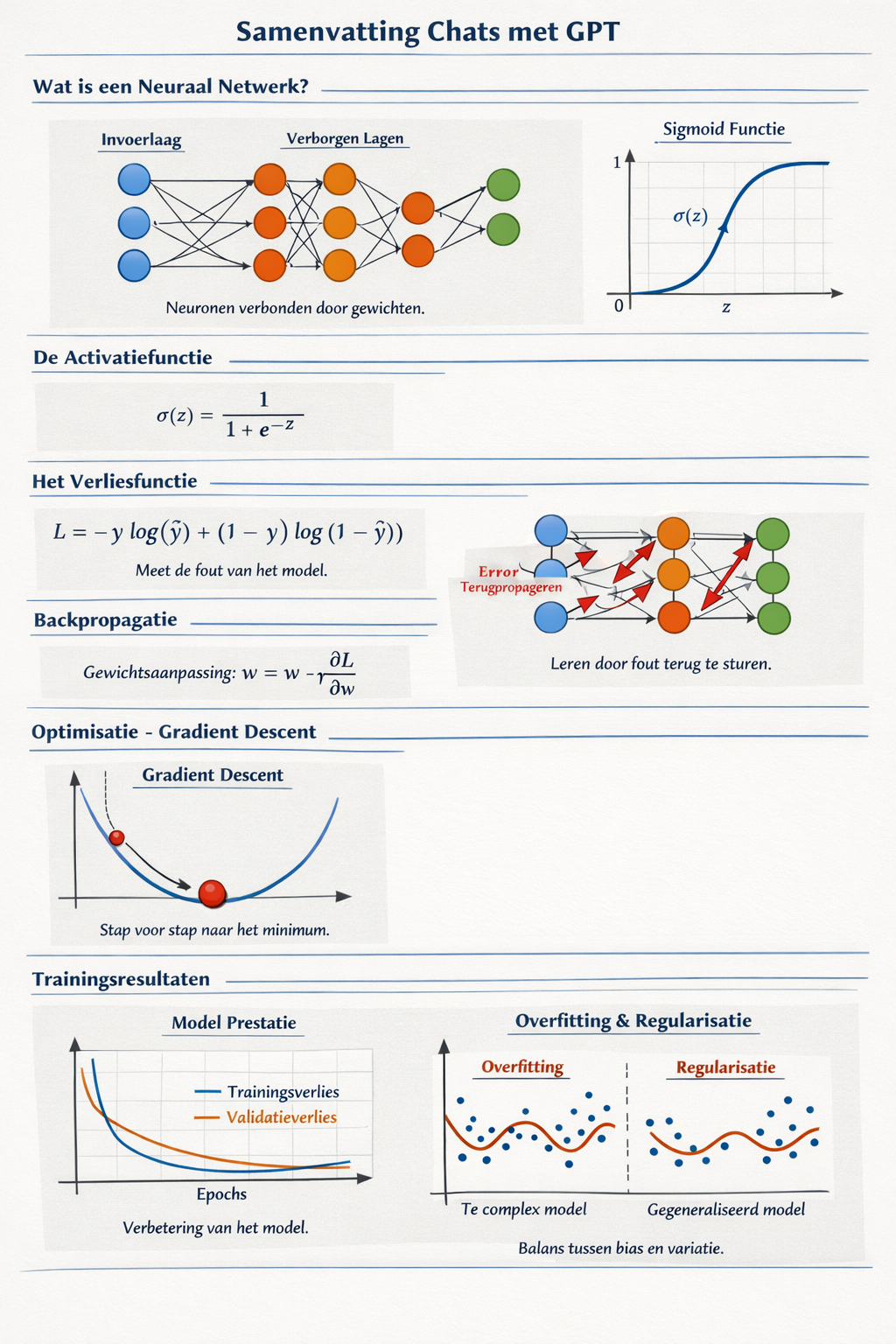
Chronologische samenvatting van de geleerde onderwerpen
Deze pagina bevat een samenvatting van de gesprekken over neurale netwerken, deep learning en bijbehorende technieken. Het overzicht is chronologisch opgebouwd en wordt ondersteund met afbeeldingen, diagrammen en gerenderde formules. De tabel met gebeurtenissen aan het einde geeft een handig tijdsoverzicht.
Vroege ontwikkelingen
In 1958 ontwikkelde Frank Rosenblatt de perceptron, een algoritme voor patroonherkenning dat een inputlaag, een verborgen laag met willekeurige (niet‑lerende) gewichten en een outputlaag beschrijft[1]. Zijn werk werd beïnvloed door ontdekkingen van Hubel en Wiesel in de visuele cortex, die verschillende typen cellen identificeerden[1]. De perceptron berekent een lineaire combinatie van inputs en past een stapfunctie toe om een klasse te voorspellen.
Ondanks vroege successen stokte het onderzoek na kritieken van Minsky en Papert (1969) op de beperkingen van perceptrons[1]. Toch werden belangrijke uitbreidingen voorgesteld, waaronder de group method of data handling (GMDH) en een meerlaagse perceptron getraind met stochastische gradient descent[1].
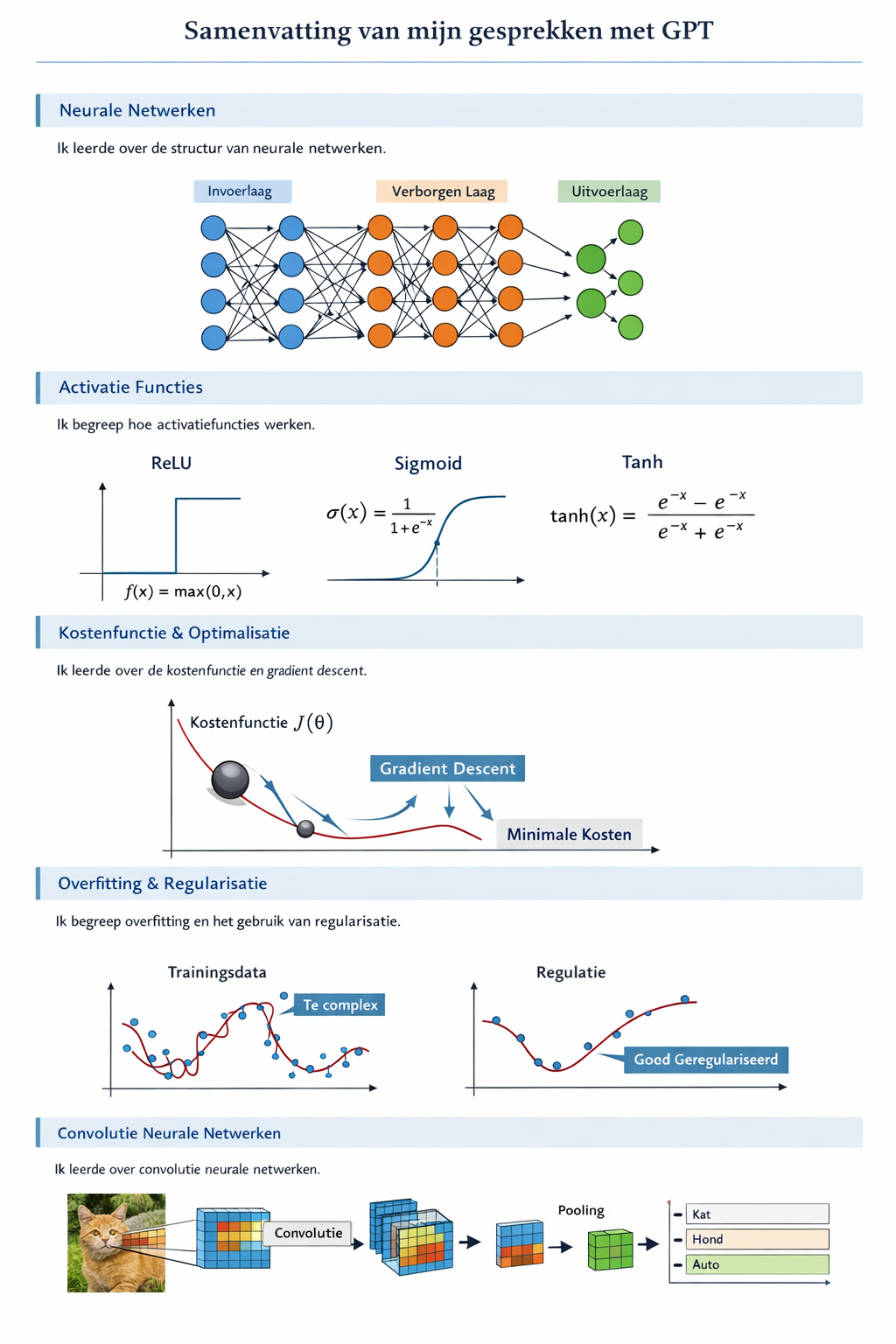
Schematische weergave van een feedforward neurale netwerk met input‑, verborgen‑ en outputlaag.
Training en optimalisatie
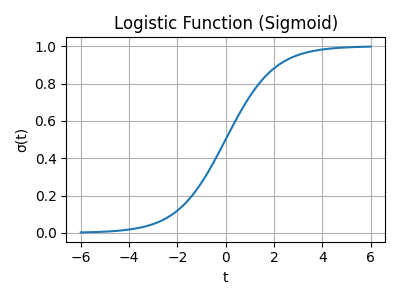
Voor classificatieproblemen wordt vaak logistische regressie gebruikt, waarbij de logistische functie (ook wel sigmoid) een lineaire combinatie van inputvariabelen naar een kans in het interval \(0\)–\(1\) projecteert. De standaard logistische functie is gedefinieerd als \(\sigma(t) = \frac{1}{1+e^{-t}}\)[2]. Wanneer \(t\) een lineaire functie is van de input \(x\), bijvoorbeeld \(t = \beta_0 + \beta_1 x\), dan geldt \(p(x) = \sigma(\beta_0 + \beta_1 x)\)[2]. De inverse functie, de logit, levert een log‑oddsverhouding \(g(p(x)) = \ln\left(\frac{p(x)}{1-p(x)}\right) = \beta_0 + \beta_1 x\)[2].
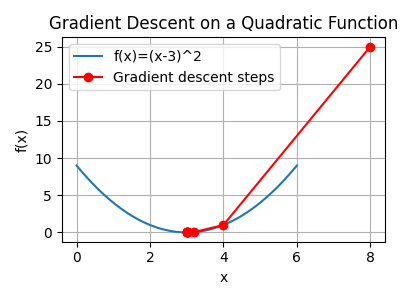
Het optimaliseren van neurale netwerken gebeurt doorgaans met gradient descent en zijn varianten. In eenvoudige vorm wordt een parametervector \(\mathbf{a}\) iteratief geüpdatet volgens \(\mathbf{a}_{n+1} = \mathbf{a}_n - \eta_n \mathbf{p}_n\), waarbij \(\eta_n\) de stapgrootte is en \(\mathbf{p}_n\) een richting die gerelateerd is aan de negatieve gradiënt[3]. Door een geschikte keuze van richting en stapgrootte kan de doel‑functie worden geminimaliseerd[3]. Voor niet‑lineaire optimalisatieproblemen wordt vaak stochastische gradient descent (SGD) gebruikt, waarbij elke update op basis van een minibatch wordt uitgevoerd.
Grafiek van de logistische functie \(\sigma(t) = 1/(1+e^{-t})\).Voorbeeld van gradient descent: stappen van een startpunt naar het minimum van de functie \(f(x)=(x-3)^2\).
Terugpropageren (Backpropagation)
Een doorbraak in het trainen van meerlaagse netwerken kwam met het backpropagation-algoritme. Backprop is in essentie een efficiënte toepassing van de kettingregel op neuraalnetwerken[4]. Het berekent de gradiënt van een verliesfunctie ten opzichte van de gewichten door de fout van de outputlaag terug te propagateren naar de inputlaag en zo redundante kettingregelberekeningen te vermijden[4]. Hierdoor konden meerdere lagen leren, wat eerder door de perceptron‑kritiek als onhaalbaar werd beschouwd.
Rumelhart, Hinton en Williams populariseerden backpropagation in 1986[1]. De methode wordt meestal gecombineerd met stochastische gradient descent: na het berekenen van de gradiënten over één of meerdere voorbeelden worden de gewichten aangepast in de richting van de negatieve gradiënt[4].
Recurrente netwerken en LSTM
Recurrente neuraalnetwerken (RNN’s) breiden feedforwardnetwerken uit met lussen zodat informatie over tijd kan worden opgeslagen. De term recurrent verwijst naar dergelijke lus‑achtige structuren[1]. Vroege RNN‑architecturen waren het Jordan‑netwerk (1986) en Elman‑netwerk (1990), waarmee cognitieve processen werden gemodelleerd[1].
Een belangrijk probleem bij RNN’s was het vanishing gradient. Sepp Hochreiter identificeerde dit probleem en stelde in 1995 samen met Jürgen Schmidhuber de long short‑term memory (LSTM) voor, een RNN‑variant die speciale poorten gebruikt om relevante informatie langer vast te houden[1]. De LSTM behaalde vanaf 2006 grote successen in spraakherkenning en andere sequentietaken[1].
Schematische representatie van een recurrent neuraalnetwerk met teruggekoppelde lus.Diagram van een LSTM‑cel met vergeet‑, input‑, cel‑ en output‑poort. Deze poorten regelen de stroom van informatie en lossen het vanishing‑gradient‑probleem grotendeels op.
Convolutionele netwerken (CNN’s)
Inspiratie uit neurobiologie leidde tot convolutionele neurale netwerken. Kunihiko Fukushima introduceerde in 1980 de neocognitron, een architectuur met convolutionele lagen en downsamplingslagen die lokaal receptieve velden en gewichtdeling toepast[1]. Dit ontwerp werd later verfijnd met maxpooling[1] en toegepast op handgeschreven cijferherkenning door LeCun et al. (LeNet-5, 1998)[1].
Door hardwareversnelling (GPU’s) en verbeterde optimalisatietechnieken konden CNN’s in 2012 doorbreken met AlexNet, dat de ImageNet‑competitie won en de deep‑learningrevolutie inzette[1]. Daarna volgden nog diepere architecturen zoals VGG, Inception en ResNet.
Conceptuele illustratie van een convolutioneel neuraal netwerk: een filter schuift over een afbeelding, genereert feature maps en wordt gevolgd door pooling.
Diepe netwerken en modern deep learning
De term deep learning verwijst naar neuraalnetwerken met meerdere (diepe) lagen. Belangrijke factoren voor de revolutie waren:
Efficiënte training via backpropagation en varianten zoals momentum, Adam en RMSProp.
Specifieke hardware (GPU’s) die berekeningen versnellen[1].
Architecturale innovaties (CNN’s, RNN’s, LSTM, later GAN’s en Transformers).
AlexNet (2012) toonde het potentieel van diepe netwerken voor beeldclassificatie[1]. Sindsdien zijn transformers en attention‑mechanismen (2017) dominante modellen geworden voor taal en multimodale taken, maar die vallen buiten deze chronologische focus.
Tijdlijn met belangrijke gebeurtenissen: perceptron (1958), diepe netwerken en stochastische gradient descent (1967), neocognitron/CNN (1980), backpropagation populair gemaakt (1986), LSTM (1995), en AlexNet (2012).
Samenvattende tabel
Onderstaande tabel vat de genoemde mijlpalen en concepten samen met jaar en sleutelwoorden.
Jaar
Onderwerp
Kernpunten
1958
Perceptron
Eerste patroonherkenningsalgoritme; input–hidden–output; geïnspireerd door visuele cortex[1].
1967
Diepe netwerken & SGD
GMDH‑methode en eerste MLP getraind met stochastische gradient descent[1].
1980
Neocognitron (CNN)
Fukushima introduceert convolutionele en downsamplinglagen[1].
1986
Backpropagation
Rumelhart et al. populariseren backprop voor efficiënte gradiëntberekeningen[1].
1995
LSTM
Hochreiter en Schmidhuber lossen het vanishing‑gradient‑probleem op met speciale poorten[1].
2012
AlexNet
Diep CNN wint ImageNet; start van de deep‑learningrevolutie[1].
Bronnen: openbaar beschikbare encyclopedische artikelen en historische overzichten van neurale netwerken en deep‑learning. Zie citaties voor details.